I’ve been using ensembles of my best classifiers to slightly improve accuracy at predicting League of Legends winners. Previously I tried scikit-learn’s VotingClassifier and also experimented with probability calibration.
Since then I’ve followed up on two ideas: 1) tuning classifier weights with VotingClassifier and 2) making an ensemble that combines individual classifier probabilities using logistic regression (and other methods!).
Tuning classifier weights
The best ensemble combines gradient boosting trees and a neural network. VotingClassifier allows for weights on the individual classifiers: By default they’re evenly weighted but you can skew the voting towards one classifier. Gradient boosting is a stronger individual classifier so it should probably get more weight than the neural network.
I evaluated several weights with 10-fold cross validation. (1) Side note: This time I’m trying out Plotly because it can make charts with error bars. I’m just showing plus or minus one standard deviation on the error bars.
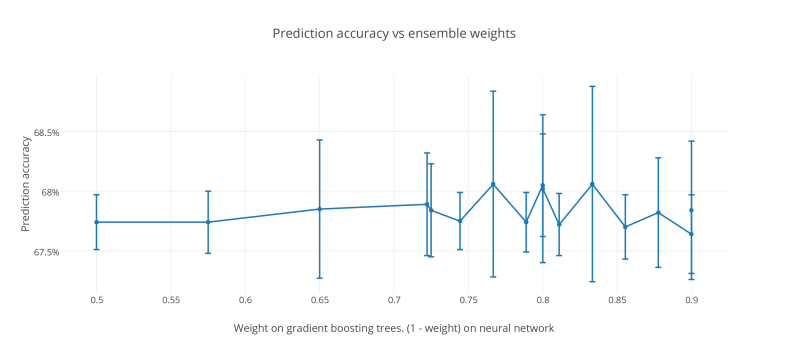
The default weights are 0.5 for each classifier.
Roughly there’s a hump around 0.8 weight on gradient boosting but it’s very rough. Almost all results are within a standard deviation of each other.
Generally I’ll stick with 0.8 weight for now. One note of caution: I’m reporting results on my overall evaluation so I’m cheating the evaluation a little in picking 0.8.
Stacking: Classifier to combine classifiers
Tuning the classifier weight bothers me. I’m tuning this equation by hand:
ensemble_prob(X) = prob_1(X) * weight + prob_2(X) * (1 - weight)
But linear regression is designed for this. I could use logistic regression to take the individual classifier probabilities as features and output the class label.
This approach is called stacking and has been used to achieve best results in several machine learning competitions. MLWave has a great section on stacking in their ensemble guide.
Stacking is a little more complex than it sounds because the output of the individual classifiers is different on training data vs unseen data. For stacking to work, the combiner classifier needs probabilities on unseen data. So to get it all to work, you need to subdivide the training data with another layer of cross-validation. (3)
Fortunately I have scikit-learn’s CalibratedClassifierCV as a guide: It uses cross-validation on the training data to learn the calibration. I created StackedEnsembleClassifier (github link) which accepts a list of base classifiers and a combiner. Regression and classification are handled differently in scikit-learn so I have a separate class to use linear regression for combination. Both of them run 3-fold cross-validation behind the scenes just like CalibratedClassifierCV.
Adding another layer of cross-validation slows training so I’ve focused on the 50k dataset. To try and compensate for higher variation in the small dataset I’ve run these tests with 20-fold cross-validation rather than the usual 5 or 10.

Linear regression is surprisingly good as a combiner. The weights are around 0.35-0.45 on gradient boosting at this data size and the two model weights sum to about 1. For this dataset the manually-tuned weighting is fairly bad, barely improving over the individual classifiers.
Logistic regression and neural networks are also quite good. One thing with the neural network is that it’s much better with sigmoid than ReLU (probably because sigmoid is smoother).
Random forests don’t work well. It could be because they’re so poorly calibrated. I tried a second implementation in which I use the predict method of the combiner rather than predict_proba but that doesn’t do well with random forests either. I’ve seen other researchers use them successfully as combiner so I may just need to add hyperparameter tuning.
I also ran limited tests on the 200k dataset with 10-fold cross-validation:

First off, gradient boosting has huge variation from one run to the next (even though it’s an average of 10 cross-validation runs and the cross-validation has a fixed random seed). My first run had learning rate 0.2167 but I’ve been using 0.221 for the ensemble. Usually I’ve seen it around 67.8% accurate.
The ensemble is somewhat helpful with 200k data points but not nearly as much as the 50k dataset. It’s plausible that I’ve tuned my hyperparameters for the individual classifiers too much on the 200k data and they need to overfit more for the ensemble to be effective. (2) It’s also plausible that I’m at the limit of predictability with this data.
Another interesting find is that linear regression picks weights around 0.5-0.6 on gradient boosting in contrast with the hand-tuned 0.8. Also I found that fit_intercept=False is slightly better.
I found that increasing the number of folds in the nested cross-validation for the ensemble is slightly helpful. But it increased runtime multiplicatively so 3 folds is enough.
The stacked ensembles tended to have lower standard deviation than the manually weighted ensemble. Particularly the logistic regression combiner tends to have lower standard deviation (i.e., it’s more dependable). That said, we should expect the stacked ensembles to have lower standard deviation because we have 2 base classifiers times 3 folds rather than simply 2 base classifiers. In other word, the cross-validation used to train the combiner smooths out some of the randomness in the individual models.
Although the runtime is higher, I feel much more comfortable with linear regression and logistic regression stacking than manual weighting of the ensemble. Partly it’s better science but they’re also more reliable.
Next steps
I don’t think focusing on better ensembles will get me much gain but I suspect that what I’ve learned will be useful. There are a few little ideas I didn’t investigate but that I’d like to someday:
- It’d be great to merge the linear regression code in with the general stacked classifier.
- Diversity among the ensemble members is important and I’d like to explore some automation to encourage diversity, possibly a grid search over the ensemble member hyperparams much like VotingClassifier. There might be en efficient way to do this if I have a larger ensemble (say 10 variations) and do a single training/testing pass to select a diverse subset to then use in the real ensemble. Or I could just tweak the parameters to overfit somewhat.
- Still need a way to have ensemble members use different subsets of the features.
- Training time is too slow. Maybe there’s a way to mimic LogisticRegressionCV for other classifiers by designing a sort of warm_start for each classifier.
Notes
- Even with 10-fold cross-validation the randomness is just too much. Maybe 20-fold would’ve been smoother. Also note this graph is a composite of 3-4 searches over ensemble weights so that’s why the points aren’t uniformly spread out.
- Saying they need to overfit is a bit counterintuitive. Really what I need is to increase the overall diversity of the ensemble. By making nice general individual models I may have forced them to output similar classifications.
- I learned the hard way that held-out data is necessary. I was trying to save some effort and just train on probabilities on the training data. But it’s even worse than the worst classifier in the ensemble! In the one test I recorded, training a logistic regression ensemble this way got 65.0% accuracy vs 66.3-66.4% from the individual classifiers.

Thanks for the StackedEnsembleClassifier, I’ll check it out when I come home from work. On another note, for some reason, sklearn’s soft voting ensemble hangs on me… Did you encounter any similar bugs?
I haven’t had that issue with soft voting but occasionally I have an issue where some models hang with no CPU usage, stuck in joblib. If I set N_JOBS=1 that fixes it but it only happens occasionally, I think when I mix training of regular models and Keras NN models.
I suspect the culprit is this incompatibility between joblib and OpenBLAS. But I haven’t looked into it further.